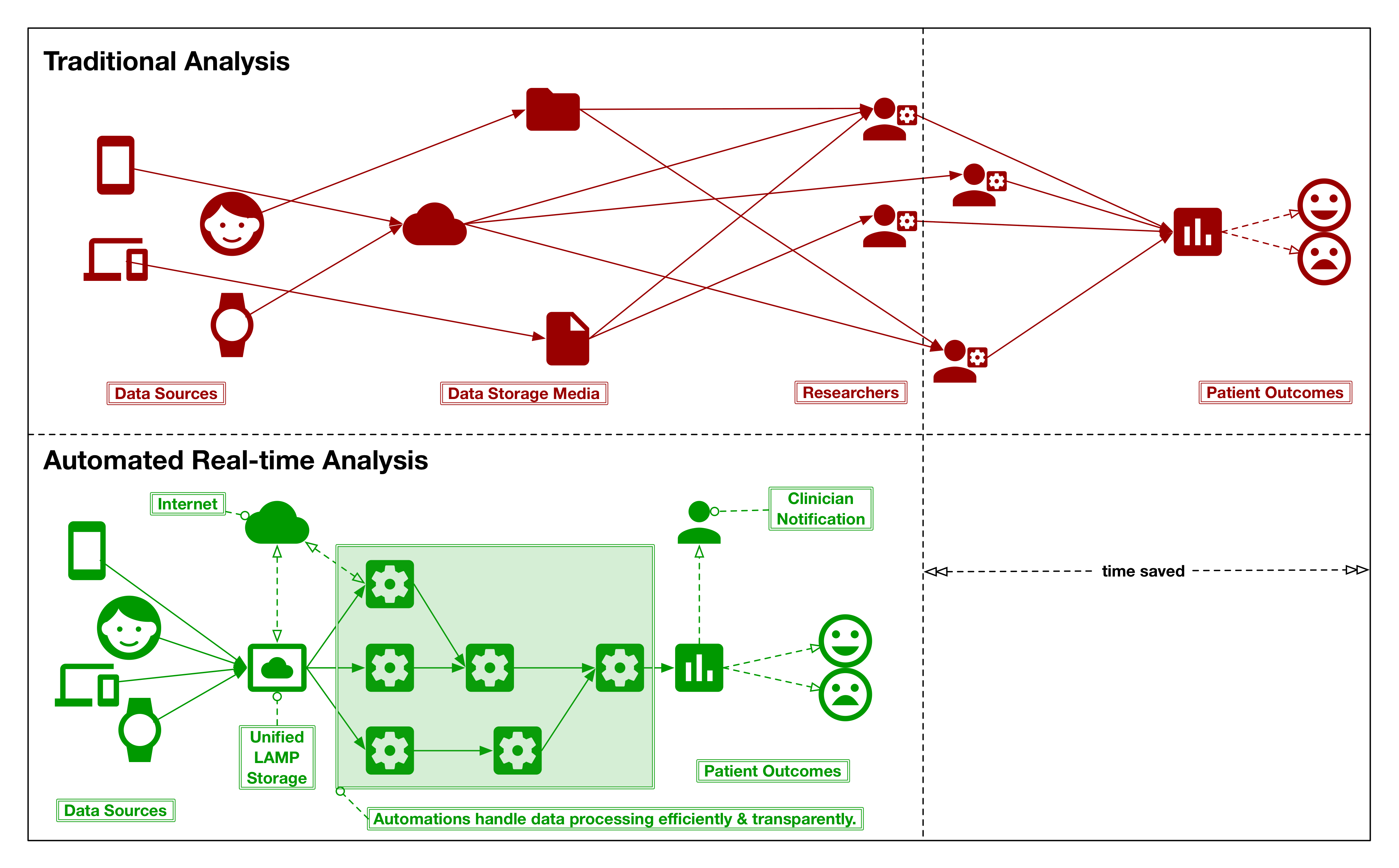
How the Platform Works
The LAMP Platform always collects data in a secure way before automatically processing and harmonizing it for you. Researchers/clinicians, and patients/participants can view their data in the frontend user interface. Patients will always retain ownership when contributing their data to your study or clinic and may always download and view their own data. Cognitive tests and survey instruments collect high quality metadata that can measure attention, focus, memory performance, and more.
The LAMP Protocol, upon which the LAMP Platform is built, may also be integrated into other systems as it is intuitive, simple, and has security and privacy built-in. It models active and passive data together as evolving streams of events, and data becomes reactive and clinically actionable through user-defined applets across R, Python, and JS. Credential management is built into the object hierarchy, which uses OpenAPI and JSONSchema to mark up extensible interfaces. The industry encryption standards AES-256 and TLSv1.3 facilitate secure storage and transmission of data in a HIPAA, COPPA, and GDPR-compliant manner.
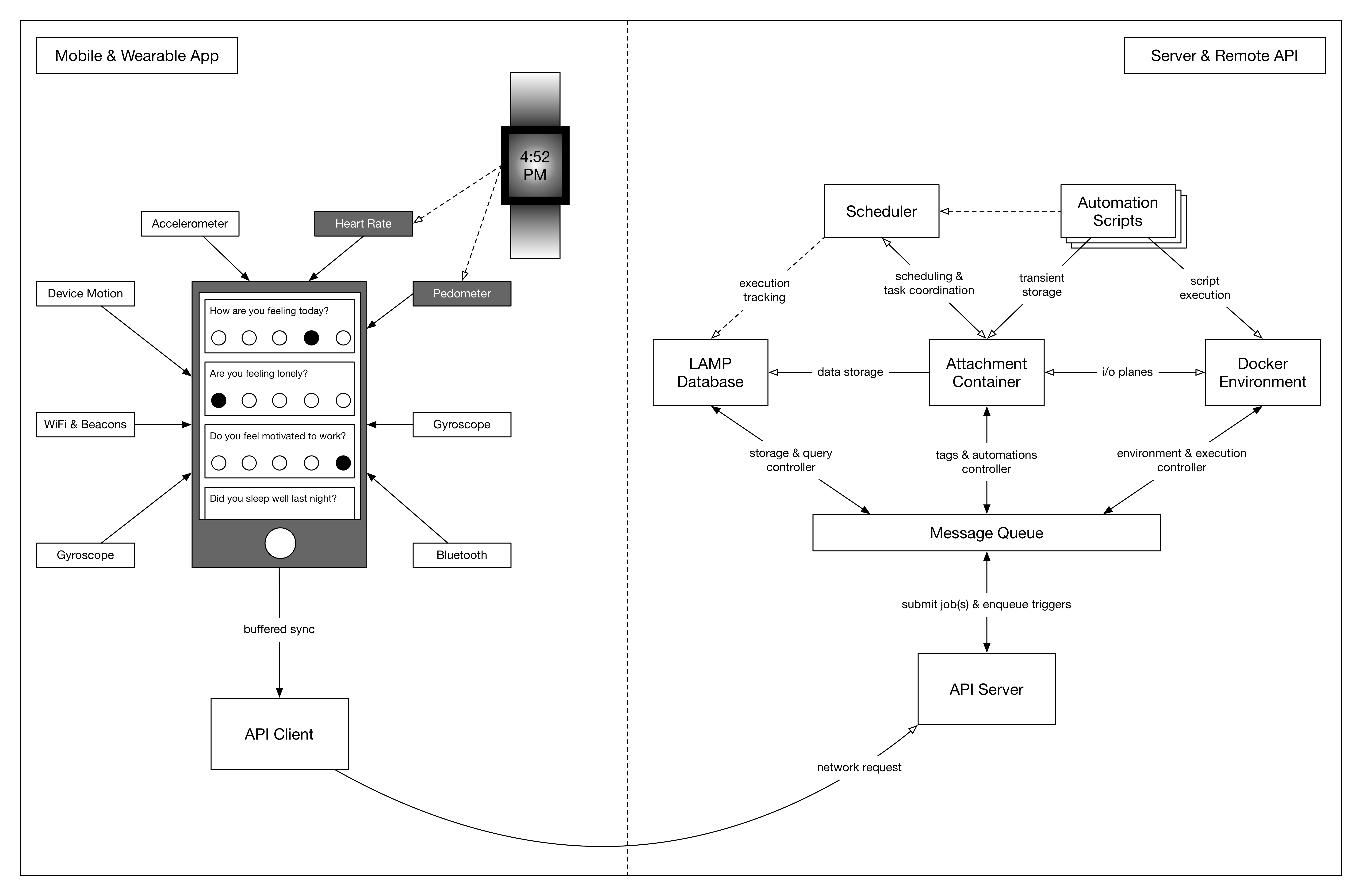
The LAMP Platform consists of two broad domains: (1) local: the components that users will see and interact with through smartphone or wearable devices, and (2) remote: the components located off-device that process data, coordinate applets, and handle synchronization. The app serves to both capture diverse streams of sensor and activity measurements ranging from heart rate to mood and to prompt suggested user interactions. It informs the LAMP Platform with a micro-temporal slice of the user’s physical and mental health. The server components supporting the LAMP Platform play an equally important role in securely encrypting and processing the data, establishing the user’s “digital fingerprint” and predicting changes that could potentially result in relapse. app-based interventions can be deployed to improve the user’s health and relevant health data can automatically be shared with authorized care team members.
The figures below detail one operation typically performed by the LAMP Platform. Shown on the left-hand side is the app, and on the right-hand side is the server. Note that both pieces consist of numerous components that work together as a modular distributed system to transfer and process data in a clinically relevant context. A full specification of all components and their interactivity is documented in later sections. Please note that an important distinction in naming is made between the local and remote domains: the components of the former are prefixed with “mindLAMP” where the components of the latter are prefixed only with “LAMP” as this distinction clarifies the scope and requirements of the components themselves.
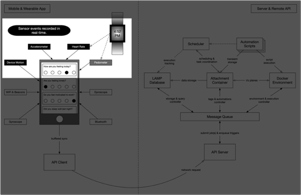
Step 1: Sensor events are recorded in real-time.
High-frequency sensors on the mobile or wearable device record measurements based on the user’s current configuration settings defined by an administrator. This data is stored in a buffer on the device's hardware managed by the operating system (either iOS or Android) and provided to the app periodically while it is in the background.
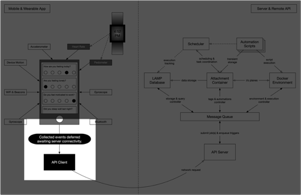
Step 2: Collected events are cached, awaiting server reachability.
The device’s buffer and operating system make no guarantees to save data from the current moment for the next time the app is run in the background. Because of this and the likelihood that the remote server may not be reachable due to poor signal, the measurements are immediately cached by the app whenever it is notified in the background. When battery levels are sufficient, and network connectivity to the remote server available, and enough data is cached, the app begins synchronization.
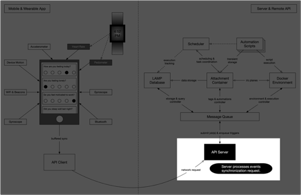
Step 3: Server receives and processes requests from the app.
The app submits a request to the server for synchronizing and uploading its cached data. Once uploaded successfully, it is unpacked and examined by the server for further automated processing.
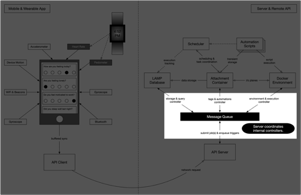
Step 4: Server coordinates internal components for processing.
The server prepares instructions for internal components based on the data uploaded by the app. These instructions are pushed through the internal data bus (a message queue) that connects all internal controllers in the platform. The extensibility of the internal components and the data bus interconnecting them means components can be swapped out or replaced depending on context. In deployments or regions where some features should be disabled, their relevant components are "unplugged" from this data bus.
Step 5: Database records the incoming data.
Depending on the server’s system configuration and the content of the data uploaded, the database then records all event data and schedules an automated backup. The database considers the origin of the events as it saves them, harmonizing data from various sensors through a unified schema.

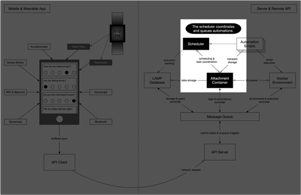
Step 6: The scheduler coordinates and runs automations.
Once the database completes saving data and any backup processes, the scheduler component is engaged to determine if any data processing “applets” or other internal maintenance tasks need to run. After assessing cost and priority, the scheduler creates an execution plan consisting of the above and notifies these components. The scheduler relies on heuristics gathered from audit logs to determine the plan.
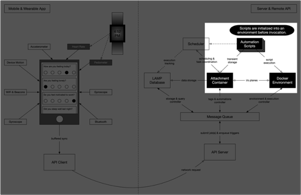
Step 7: Applets are launched into a safe environment and run.
Assuming no internal maintenance tasks need to run, the scheduler may create an execution plan with only a single applet. Once started, a new virtual environment is prepared and securely isolated from other data. For example, an R environment would analyze the script to run and install the correct versions of all required packages, replicating the environment used by the applet's author.
Please contact us directly for guidance on delivery of just-in-time interventions.
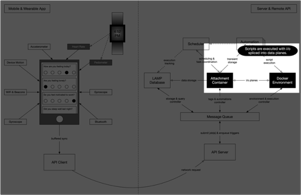
Step 8: Applet results are saved after being run.
As the applet executes, its input and output are spliced from the automation controller and saved as tags. For example, an applet called "com.test.some_script" may create a new tag “com.test.some_script” attached to some resource in the database, or append to an existing tag with the same name. Any runtime logs are extracted separately from this result.
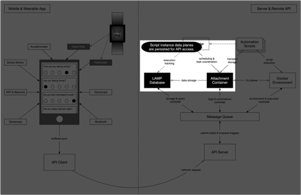
Step 9: Applet results are persisted for later access.
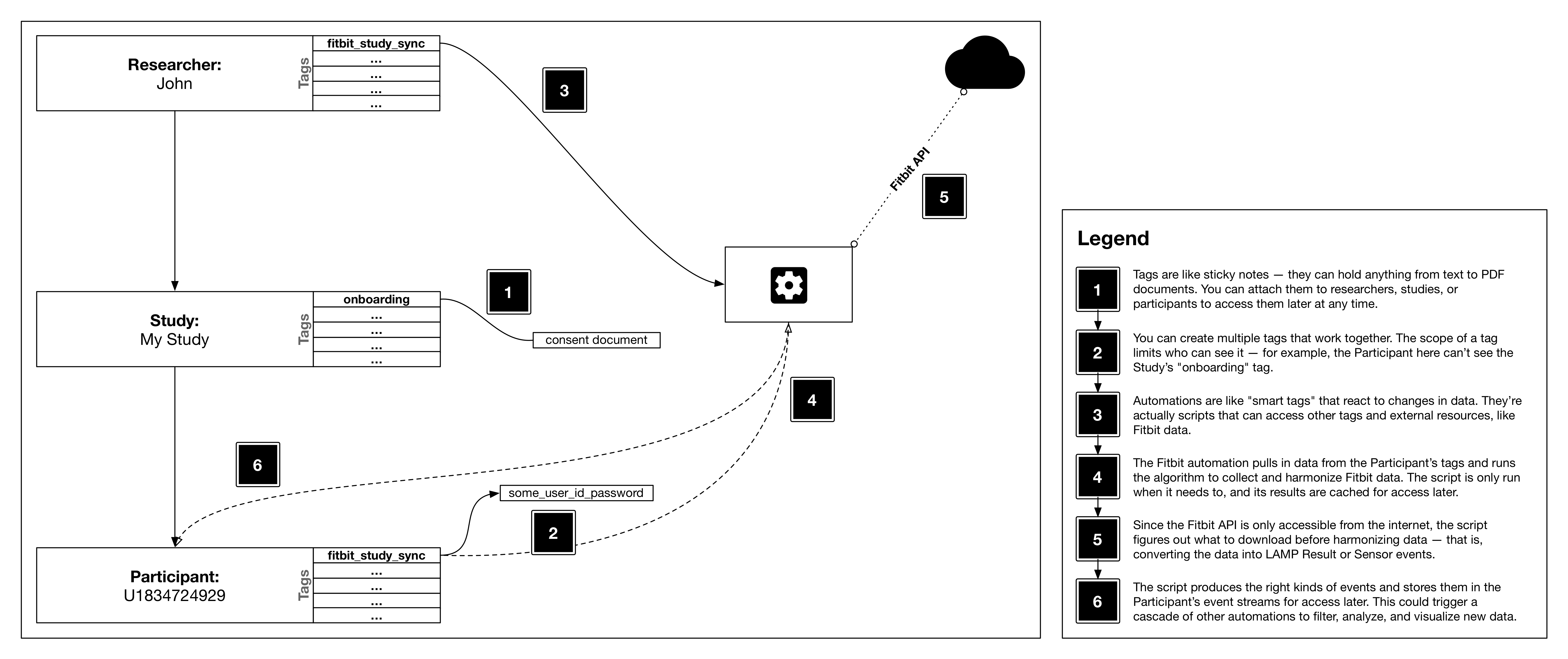
If an applet is configured to persist its output, the data are persisted to the database as a tag and may be accessed by a client app directly at a later time. For example, an applet may compute a dynamic visualization to be cached, or it could lookup login credentials from a predefined tag to access and convert data from a third-party system such as Fitbit into native resource objects which are then persisted by the database.
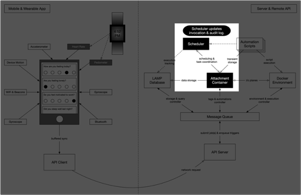
Step 10: Scheduler updates invocation and audit log.
Once an execution plan completes, the scheduler records statistics about it for its next engagement.
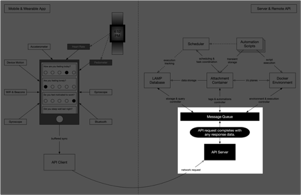
Step 11: Request completes with any response data.
If any controller responds to their currently executing instruction with a response payload (such as the execution output of an applet), it is bundled and returned to the API client synchronously. If a controller needs more time to process an instruction, it can return a pointer to an operation resource that can be used in a later asynchronous request to the server to locate the response once completed. If a controller chooses to respond to an instruction but is unable to complete it, the response returns immediately to the client app as an error.
Tags & Automations
Automations are a flexible framework for the LAMP platform that allow you to run complex analytics and decision support tools either in reaction to new events in an event stream, or on a periodic schedule. Without having to configure a processing pipeline for system requirements such as CPU, I/O, or RAM, automations abstract the functional logic from data resources and system requirements. Automations support simple, flexible, and portable code that can run on low-power devices such as smartwatches or older smartphones all the way up to large servers and computing clusters in the cloud.
These "applets," called Automations, can be written in typical data science programming languages such as JavaScript, Python, and R, with any packages or dependencies automatically bundled within. When installed onto a Resource (that is, a Researcher, Study, Participant, or even an Activity), it is capable of listening to events generated by that Resource. For example, if installed for Participants, one such applet could listen to any SensorEvents or ActivityEvents, or when installed for Activities, it could listen only to anonymized ActivityEvents generated by any Participant. When the Cloud server receives new events, it prepares all Automations that fit the specified event mask and allows them to execute with preallocated hardware limits.
Tags as Arbitrary Data on Resources
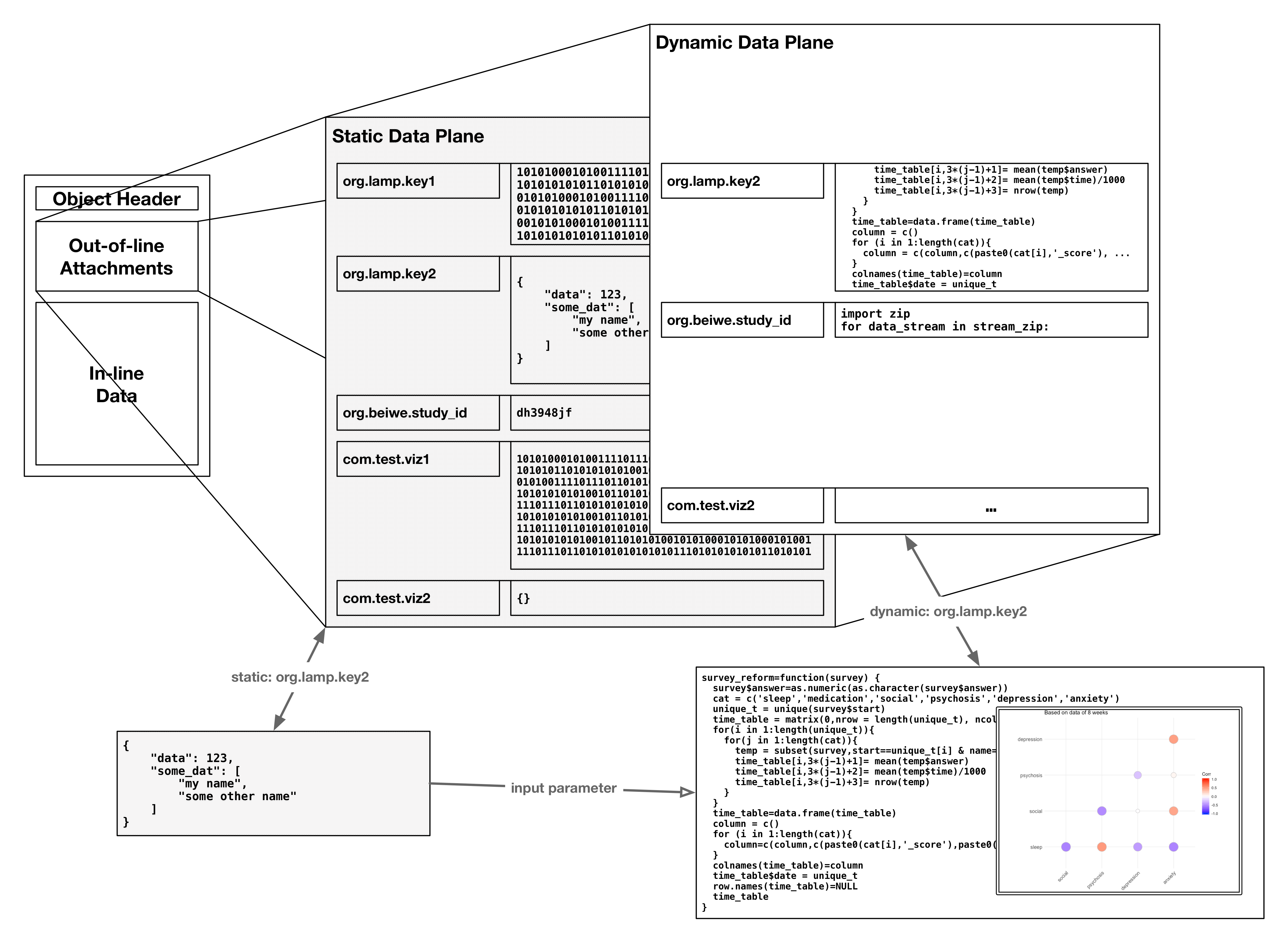
Tags are an arbitrary unit of extensibility available to all Resource sub-types. Through string-indexed/keyed subscripting, out-of-line data may be attached to objects in the LAMP Platform as an ad-hoc micro-database. For a flow chart on the usage of Tags, see the figure below. Tags are a powerful tool that may be leveraged by clients of the LAMP Platform to build applets for the Platform as well as smaller apps within such client apps themselves.
Data-URI strings in Tags
Tags may consist of JSON object, array, or primitive types, as well as encoded data-uri strings (to represent binary data like PDFs or MP3s). data-uri strings are normal string primitives but prefixed with data:<mime_type>[;base64], where <mime_type> refers to the binary application file type of the data that follows, such as application/json, text/plain; charset=utf8, or image/svg+xml. If the base64 optional parameter is provided, the contents of the string following the comma are to be base64-decoded when interpreted by the LAMP Platform or clients of the LAMP Protocol. Specifying an optional Accept header type may optionally allow the LAMP server component or other LAMP Protocol vendors to automatically convert such data-uri strings into a binary type.
Atomic Indexed Access and Modification
Furthermore, to support atomic operations on Tags, an indexed modifier version of get & set methods shall exist such that for a Tag whose content is an object, the method GET | POST /type/<id>/my.tag.name.here[/someKeyedIndex] shall return or replace only the sub-content of the object but not the whole object represented by the Tag. For JSON arrays, keyed indices shall take the form of continuous numbered indices found in the array itself, including the special index length which shall only return but not replace the length of the underlying array. Through these rudimentary atomic mutation facilities, vendors and clients of the LAMP Protocol may perform basic synchronization without poll-waiting or SSE (Server Sent Events) reconciliation.
Automations as Multidimensional Planes of Data within Tags
Automations shall be represented by their specific LAMP Protocol object schema, but encoded as a plaintext JSON data-uri string with the mime type application/vnd+lamp.automation. When registering or unregistering an Automation’s availability with a LAMP server or other component, the component itself shall maintain a running record of compute images, trigger-points, and code for each Automation. When the Tag containing the Automation data is removed, the Automation itself shall be unregistered and made no longer functional in that instance of the LAMP Platform. The figure below describes the relationship between the static data plan (Tags) and the dynamic data plane (Automations) which leverage the functionality described in prior chapters to perform Just-In-Time intervention, prediction, analysis, visualization, or some other set of relevant functions. This functionality has also been superceded by the TagSpec API.
Federated Systems Using the Automation Framework
Supposing multiple existing systems provided clinically useful sources of data, such as longitudinal imaging repositories or existing Fitbit devices synchronized to the cloud. While data retrieval and ad-hoc storage of “out-of-line” (that is, unrecognized by the Platform, but retaining meaning to its owner) data from within the Platform is simple using the API, it would be simply infeasible to manually verify modified data against multiple specific conditions and run several scripts in the Researcher’s local computer before sending out notifications or awaiting further processing from elsewhere. Instead, the Platform supports, through the Automations framework, a method of dynamically running such scripts as “applets” atop extremely powerful unconstrained hardware not managed by the Researcher or their IT department.
In the example above, a combination of two applets and an external Amazon S3 database (unknown to the LAMP Platform) provide the equivalent three step upload-process-analyze functionality of apps such as AWARE, Fitbit, Beiwe, Google Fit, and more. The lamp.anomaly_detection applet is not considered a part of this group as it was written to use only the standard API provided by the LAMP Platform; it contains no knowledge of the other two applets and the external database. The org.aware.upload applet requests preallocation of storage, perhaps on the order of ~5GB, but entirely variable depending on the Participant’s device or historical data uploads. It then returns a response immediately to the requesting smartphone device or internet service with a URL to which it can upload the data. The second applet, org.aware.processing is instead run by the Cloud server every 5 minutes to check if any processing needs to be done in the database, and if so, executes the processing, but otherwise does nothing. This applet converts the uploaded data to LAMP Resources (ActivityEvents or SensorEvents, specifically) and submits them to the Cloud server in bulk. Just as with any other events received by the Cloud server, it will then execute a set of Automation applets — in this case, lamp.anomaly_detection. In summary, with this multi-applet workflow, data is automatically uploaded and stored in an external database wholly maintained by a third-party, subsequently converted to actionable reactive LAMP Sensor or ActivityEvents, and finally analyzed through the same methods as all other data.